第一部分:安装。
1、安装。
数据库官网下载免费安装,选择典型安装。安装完成后可勾选继续配置文件。
也可单独配置MySQL:
先找到位置:C:\Program Files\MySQL\MySQL Server 5.5/bin/mysqlinstanceconfig.exe文件。然后点击5.5版本,选择标准配置。默认选定三个复选框安装windows服务。设置2次密码进行下一步,执行下一步完成配置。
判断是否安装完成:1、在电脑右键管理,里面服务。是否可以找到mysql启动。2、电脑属性→高级→环境变量→path→有BIN子目录下的可执行文件。
MySQL目录结构:
bin目录,存储可执行文件
data目录,存储数据文件
docs,文档
include 目录,存储包含的头文件
lib目录,存储库文件
share ,错误消息和字符集文件
找到my.ini配置文件修改编码方式:
将[client]、和[mysqld]下的
port=3306 默认端口号
[mysql]
default-character-set=utf8
character-set-sever=utf8 将原来的拉丁改成utf8 重新启动。启动方式:可以在服务里面重启。或则在运行CMD里面采用命令: 先停止命令 net stop mysql 再启动 net start mysql
登陆退出mysql:
在CMD里面运行命令:C:\Windows\system32>mysql -V这个是显示mysql版本信息
Mysql 参数: -D,--database=name 打开指定数据库
--delimiter = name 指定分隔符
-h,--host=name 服务器名称(本地服务器IP:127.0.0.1)
-p,--password[=name] 密码
-P,--port=# 端口号
--prompt=name 设置提示符
-u,--user=name 用户名
-V,--version 输出版本信息
退出mysql: 在里面执行命令exit quit \q 都可以退出。
修改mysql提示符:
连接客户端时通过参数指定 shell>mysql -uroot -proot --prompt 提示符 注释:-u后面是用户名 -p后面是密码
连接上客户端后,通过prompt命令修改
Mysql>prompt 提示符
提示符后面可以跟的参数 \D 完整的日期
\d 当前数据库
\h 服务器名称
\u 当前用户
例子: mysql>PROMPT \u@\h \d>
回车显示结果: root@localhost (none)>
第二部分:创建数据表、列的属性,以及查询数据表,修改数据表等。
2、Mysql 常用命令:
SELECT VERSION(); 显示当前服务器版本
SELECT NOW(); 显示当前日期时间
SELECT USER(); 显示当前用户
Mysql 语句的规范:
①、关键字与函数名称全部大写。
②、数据库名称、表名称、字段名称全部小写。
③、SQL语句必须以分号结尾。(没有分号会出现->)
命令:说明:{} 里面内容必写; [] 里面内容可选;
创建数据库:CREATE {DATABASE | SCHEMA} [IF NOT EXISTS] db_name [DEFAULT] CHARACTER
SET [=] charset_name
查看数据库列表:SHOW {DATABASES | SCHEMAS} [LIKE ‘pattern’ | WHERE expr]
查看警告信息:SHOW WARNINGS;
查看数据库(名称t1)的编码方式:SHOW CREATE DATABASE t1;
修改数据库:ALTER {DATABASE | SCHEMA} [db_name] [DEFAULT] CHARACTER SET [=] charset_name
删除数据库:DROP {DATABASE | SCHEMA} [IF EXISTS] db_name
例子:CREATE DATABASE t1;
CREATE DATABASE IF NOT EXISTS t2 CHARACTER SET = gbk;
ALTER DATABASE t2 CHARACTER SET gbk;
Mysql安装成功后默认自带4个数据库。
3、数据类型:是指列、存储过程参数、表达式和局部变量的数据特征,它决定了数据的存储格式,代表了不同的信息类型。【比如有些数据类型需要存储为数字,而数字可能存储为小数、整数、日期以及字符型】
①、整型。有以下五种
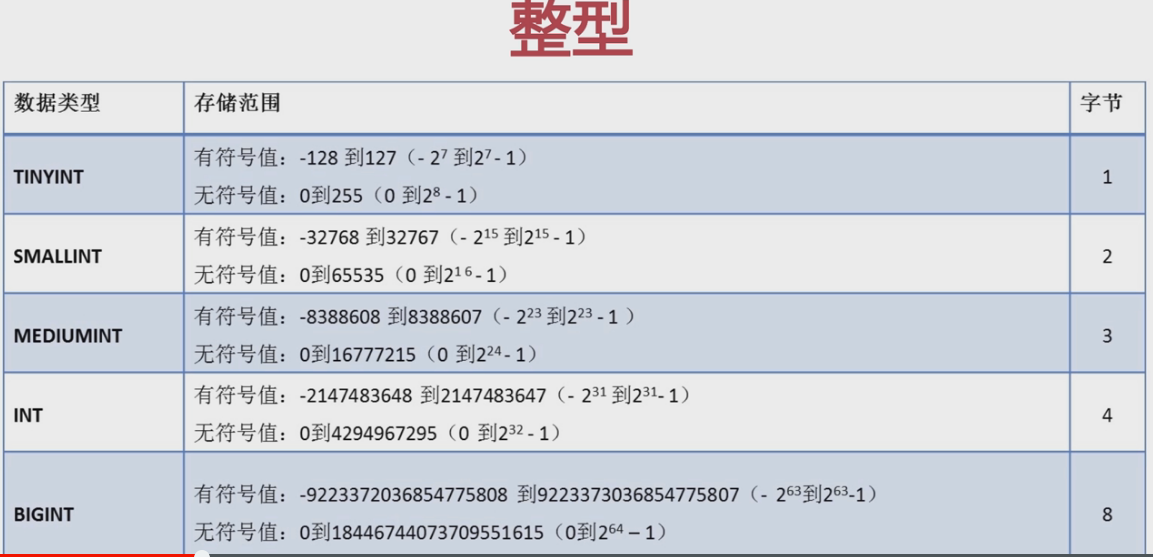
选择存储的数据类型,主要是和后面的字节有关,我们要选择最合理最合适的数据类型。
UNSIGNED 无符号的,无正负之分的;
②、浮点型。

一般常用的是FLOAT[(M,D)] (因为存储空间更小,用的比较广泛。) 例子:FLOAT[(7,2)] 最高存储99999.99 即小数点前面5位后面2位。
③、日期时间型。
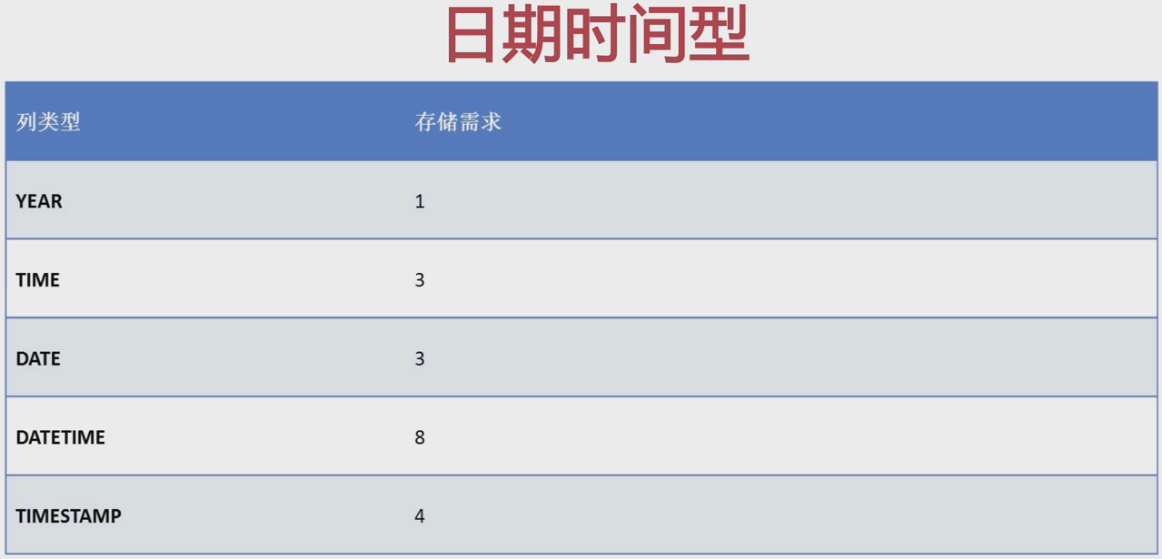
DATE 存储时间范围1000年1月1号—9999年12月31号
DATETIME 存储时间范围1000年1月1号0点—9999年12月31号23点59分59秒
TIMESTAMP 存储时间范围 1970年1月1号0点—2037年12月31号23点59分59秒
TIME 存储时间范围 -8385959 — 8385959
YEAR 存储时间范围(默认存储4位,也可以存储2位) 存储范围 1970年-2069年 这个用的比较少,因为存在一个时区的问题。所以出现这类的时间会用数字类型来存储。
④、字符型。
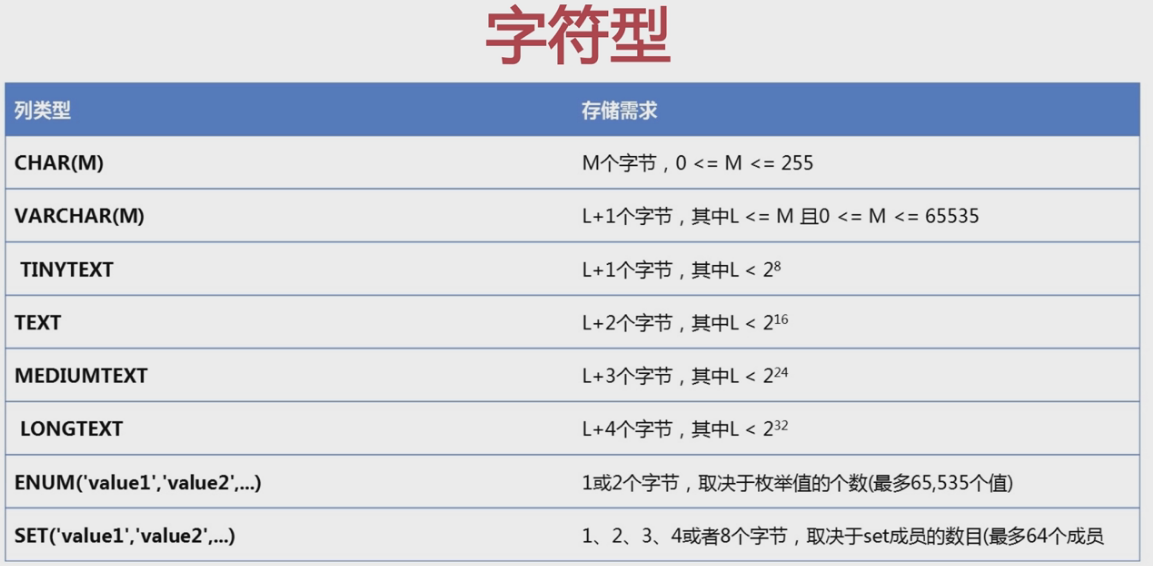
CHAR(M) 类型称之为定长类型,例如:CHAR(5) 而我们写值时输入了ABC,那么要补充到5位。即ABC (ABC后面跟2个空格补充到5位。)
VARCHAR(M) 类型称之为变长类型,例如:VARCHAR(5) 输入了ABC,存储时还是ABC
1k=8bit 1k最大存储的范围是11111111 就是10进制中的2 8次方255,而2k就代表最大存储范围是 1111111111111111 即10进制中的 2 16次方
L+1 个字节的意思就是最大存储范围是 2 8次方+1
ENUM(‘value1’,’value2’,...) 枚举值就是所给的几个选项(比如性别:男、女、保密),只能从这几个值当中去选。
SET(‘value1’,’value2’,...) 集合(做排列组合)。例如:给A、B、C三个值。那么可选A、AB、ABC、BC、AC 。取决于SET成员的数量。
4、数据表(或称表)是数据库最重要的组成部分之一,是其他对象的基础。
表的行称之为记录,列称之为字段。没有数据表的数据库只是一个空架子。如果要存储数据,就需要设计数据表。而这之前需要打开数据库。方法:USE 数据库名称。为验证该表格是否被打开,可使用命令 SELECT DATABASE(); 测试。
命令:创建数据表
CREATE TABLE [IF NOT EXISTS] table_name(
column_name data_type,
.....
);
注意:创建表的table_name 名字和里面的数据名称 column_name 及其数据类型data_type都是要通过和项目匹配精心设计的。两个字段之间用 , 作为分隔符,最后一个字段不用。
5、命令:查看数据表。
SHOW TABLES [FROM db_name]
[LIKE ‘pattern’ | WHERE expr]
例子:SHOW TABLES FROM mysql; 就会显示mysql里面所有的数据表,但不会改变当前打开表格的位置。可以用命令验证 SELECT DATABASE();
命令:查看数据表结构。
SHOW COLUMNS FROM tbl_name; //COLUMNS 表中的列
命令:向数据表中写入数据(插入记录)。
INSERT [INTO] tbl_name [(col_name,...)] VALUES(val,...);
例子:INSERT tb1 VALUES(‘TIM’,25,6221); 注意:此时后面的数据要匹配,少了一个会报错。而且好像名字也不能用中文。 但是可以通过这样的方法来重新定义输入数据。
INSERT tb1(username,salary) VALUES(‘JOHN’,4500.69);
命令:查看记录(记录查找)。
SELECT expr,.... FROM tbl_name;
例子:SELECT * FROM tb1;
字段属性:空值与非空。
在字段输入时期 加入NOT NULL ,字段禁止为空。(默认允许为空)。
例如:CREATE TABLE tb2(
-> username VARCHAR(20) NOT NULL,
-> age TINYINT UNSIGNED NULL
-);
字段属性:AUTO_INCREMENT
注意:自动编号,必须与主键组合使用(而主键不一定需要和AUTO_INCREMENT一起使用,如例子2)。默认情况下,起始值为1,每次增1.
例子1:CREATE TABLE tb3(
-> id SMALLINT UNSIGNED ATUO_INCREMENT PRIMARY KEY,
-> username VARCHAR(30) NOT NULL
-> );
例子2:CREATE TABLE tb4(
-> id SMALLINT UNSIGNED PRIMARY KEY,
-> username VARCHAR(20) NTO NULL
-> );
INSERT tb4 VALUES(22,’JOHN’); 【为tb4添加数据,包括自定义ID,ID重复会报错】
属性:PRIMARY KEY(也可以只写KEY)
主键约束;每张数据表只能存在一个主键;主键保证记录的唯一性;主键自动为NOT NULL。例子如上。
属性:UNIQUE KEY
唯一约束;唯一约束可以保证记录的唯一性;唯一约束的字段可以为空值(NULL,而且只保存一个空值。);每张数据表可以存在多个唯一约束。
例子:CREATE TABLE tb5(
-> id SMALLINT UNSIGNED ATUO_INCREMENT PRIMARY KEY,
-> username VARCHAR(20) NTO NULL UQIQUE KEY,
-> age TINYINT UNSIGNED);
INSERT tb5(username,age) VALUES(‘tom’,22);
【当再有一个tom输入时报错,因为记录有唯一约束性】
属性:DEFAULT
默认值;当插入记录时,如果没有明确为字段赋值,则自动赋予默认值。
例子:CREATE TABLE tb6(
-> id SMALLINT UNSIGNED ATUO_INCREMENT PRIMARY KEY,
-> username VARCHAR(20) NTO NULL UQIQUE KEY,
-> SEX ENUM(‘1’,’2’,’3’) DEFAULT ‘3’
-> );
INSERT tb6(username) VALUES(‘TOM’);
【即在SEX 输入时为空了,系统会默认将3赋值给SEX】
单节总结:
数据类型分为字符型、整型、浮点型、日期时间型。
数据表操作:插入记录、查找记录。数据表是其他对象的基础。
记录操作:创建数据表、约束的使用。
约束:
①、约束保证数据的完整性和一致性。
②、约束分为表级约束和列级约束。
③、约束类型包括:NOT NULL 、 PRIMARY KEY 、 UNIQUE KEY 、DEFAULT 、FOREIGN KEY
外键约束: FOREIGN KEYp
保持数据一致性,完整性。实现一对一或者一对多关系(关系型数据库)。
创建外键约束的要求:
❶、父表和子表必须使用相同的存储引擎,而且禁止使用临时表。
❷、数据表的存储引擎只能为InnoDB 。
❸、外键列和参照列必须具有相似的数据类型。其中数字的长度或是否有符号位必须相同;而字符的长度则可以不同。
❹、外键列和参照列必须创建索引。如果外键列不存在索引的话,MyAQL将自动创建索引。
注释:父表和子表相对参照表和参照表。数据表的存储引擎在配置文件MY.ini里面进行修改。外键列是指子表参照的列。参照列没有创建索引的话会自动创建,而外键列没有创建索引,则不会自动创建索引。
例子:先创建父表
CREATE TABLE provinces(
-> ID SMALLINT UNSIGNED PRIMARY KEY ATUO_INCREMENT,
-> pname VARCHAR(20) NOT NULL);
注释:这里创建ID时,加入了主键,所以创建了父表的索引。
查看是否创建好了索引,命令:SHOW INDEXES FROM provinces\G;
加上 \G是以网格的形态呈现。不加则已数据库都有的形态呈现。
再创建子表
CREATE TABLE users(
-> id SMALLINT UNSIGNED PRIMARY KEY AUTO_INCREMENT,
-> username VARCHAR(10) NOT NULL,
-> pid SMALLINT UNSIGNED,
-> FOREIGN KEY (pid) REFERENCES provinces (id));
注释:同样以命令: SHOW INDEXES FROM users\G; 会发现存在两个索引,第一个是这个本身的主键创建的索引。第二个是pid 字段上自动创建的索引。
外键约束的参照操作
①、CASCADE:从父表删除或者更新时,自动删除或者更新子表中匹配的行。
②、SET NULL:从父表删除或者更新行,并设置子表中的外键列为NULL.如果使用该选项,必须保证子表列中没有指定NOT NULL
③、RESTRICT:拒绝对父表的删除或更新操作。
④、标准SQL的关键字,在MySQL中与RESTRICT 相同。
语法结构:ON DELETE CASCADE
注意:必须在父表中先插入记录后才能在子表中插入相应记录(或者理解为只有父表中存在相应记录,子表中才能对应插入记录【如果插入失败,失败的操作会占用ID序号】)。同时:删除父表中的记录,子表中对应的记录同时会被删除。
在约束中,很少使用物理的外键约束(如引擎为indodd);经常使用逻辑约束(上述键)。
修改数据表
添加单列数据表语法:
ALTER TABLE tbl_name ADD [COLUMN] col_name column_definition [FIRST | AFTER col_name]
注释:如果没有加位置,默认最后列加。FIRST 为第一列。AFTER在需要加的那列后。
添加多列数据表语法:
ALTER TABLE tbl_name ADD [COLUMN] (col_name column_definiton,...)
注释:添加多列默认在最后列开始添加,不能定义位置。
删除列的语法:
ALTER TABLE tbl_name DROP [COLUMN] col_name
或者删除多列:ALTER TABLE tbl_name DROP [COLUMN] col_name,DROP [COLUMN] clo_name
或者删除一列的同时增加一列:
ALTER TABLE tbl_name DROP [COLUMN] col_name,ADD [COLUMN] (col_name column_definition)
添加主键约束
ALTER TABLE tbl_name ADD [CONSTRAINT [symbol]] PRIMARY KEY [index_type] (index_col_name,...)
例如:ALTER TABLE users2 ADD CONSTRAINT PK_users2_id PRIMARY KEY (id);
添加唯一约束
ALTER TABLE tbl_name ADD [CONSTRAINT [symbol]] UNIQUE [INDEX|KEY] [index_name] [index_type] (index_col_name,...)
添加外键约束
ALTER TABLE tbl_name ADD [CONSTRAINT [symbol]] FOREIGN KEY [index_name] (index_col_name,...) reference_definition
例子:ALTER TABLE users2 ADD FOREIGN KEY (pid) REFERENCES provinces (id);
添加/删除默认约束
ALTER TABLE tbl_name ALTER [COLUMN] col_name {SET DEFAULT literal | DROP DEFAULT}
例子:ALTER TABLE users2 ALTER age SET DEFAULT 15; //设置年龄默认值为15
删除主键约束
ALTER TABLE tbl_name DROP PRIMARY KEY
例子:ALTER TABLE users2 DROP PRIMARY KEY; //主键只有一个,不需要指定名称
删除唯一约束
ALTER TABLE tbl_name DROP {INDEX|KEY} index_name
注意:一张表可以有多个唯一约束,所以需要索引的名字。而且删除的是约束,并不是字段
例子:ALTER TABLE users2 DROP INDEX username;
删除外键约束
ALTER TABLE tbl_name DROP FOREIGN KEY fk_symbol
例子:ALTER TABLE users2 DROP FOREIGN KEY users2_ibfk_1;
注意:users2_ibfk_1是系统赋予的名字,通过命令:SHOW CREATE TABLE users2; 查询。
删除索引
ALTER TABLE users2 DROP INDEX pid;
修改列定义(数据列里面的各种属性和位置)
ALTER TABLE tbl_name MODIFY [COLUMN] col_name column_definition [FIRST | AFTER col_name]
例子:ALTER TABLE users2 MODIFY id SMALLINT UNSIGNED NOT NULL FIRST;
上述例子只是改变id 字段的位置,而不改变别的。
例子:ALTER TABLE users2 MODIFY id TINYINT UNSIGNED NOT NULL;
上述例子改变id字段的存储数据大小。注意:当数据表已经存在数据时,将存储范围从大类型设置为小类型,有可能丢失数据。比如上述原数据大于256,而改成存储范围在255以内,就会导致数据丢失。
修改列名称
ALTER TABLE tbl_name CHANGE [COLUMN] old_col_name new_col_name column_definition [FIRST|AFTER col_name]
例子:ALTER TABLE users2 CHANGE pid p_id TINYINT UNSIGNED NOT NULL;
修改数据表的名字
单独修改一个数据表方法1:
ALTER TABLE tbl_name RENAME [TO|AS] new_tbl_name;
例子:ALTER TABLE users2 RENAME users3;
批量或者单独修改数据表方法2:
RENAME TABLE tbl_name TO new_tbl_name[,tbl_name2 TO new_tbl_name2]...;
例子:RENAME TABLE users3 TO users2;
注意:当数据表已经存在并存储了数据,随意更改数据表名称和其中的列表名称,可能会导致某些操作失效。

第三部分:对数据表中的数据进行操作。
INSERT (插入记录)
方法一:
INSERT [INTO] tbl_name [(col_name),...] {VALUES | VALUE} ({expr | DEFAULT},...),(...),...
例子:CREATE TABLE users(
id SMALLINT UNSIGNED PRIMARY KEY AUTO_INCREMENT,
username VARCHAR(20) NOT NULL,
password VARCHAR(32) NOT NULL,
age TINYINT UNSIGNED NOT NULL DEFAULT 10,
sex BOOLEAN
);
INSERT users VALUES(NULL,’TOM’,’123’,25,1);
INSERT users VALUES(DEFAULT,’BEN’,’123’,25,1);
INSERT users VALUES(DEFAULT,’ROSE’,’123’,3*8-1,1);
INSERT users VALUES(DEFAULT,’JCAK’,’123’,DEFAULT,1);
注释:、对于ID字段自增,可以采用NULL或者DEFAULT两个值替代。而这些值不能为空,否则输入的数据与表格的列数不匹配,会报错。‚、里面的数据可以是表达式或者是函数。ƒ、有默认值的可以填写DEFAULT输入默认值。④、还可以插入多行,用逗号隔开。
方法二:
INSERT [INTO] tbl_name SET col_name = {expr | DEFAULT},...
与第一种方式的区别在于,此方法可以使用子查询(SubQuery),且一次只能插入一条记录。
例子:INSERT users SET username=’HUY’,password=’542’;
注释:该例子接上面的表,ID\AGE 字段默认可以不输入,性别字段允许为空。
方法三:
INSERT [INTO] tbl_name [(col_name,...)] SELECT ...
此方法可以将查询结果插入(存储)到指定数据表,补充例子:
INSERT test(username) SELECT username FROM users WHERE age >= 30;
注释:这是根据已有数据表的数据查询结果筛选出age大于30的username 存储到新表test
更新记录(单表更新):群更改数据库。

SELECT(查找记录)
SELECT select_xipr [,select_expr...]
[
FROM table_references
[WHERE where_condition]
[GROUP BY {col_name | position} [ASC | DESC],...]
[HAVING where_condition]
[ORDER BY {col_name | expr | position} [ASC | DESC],...]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
]
例子:SELECT VERSION();
SELECT NOW();
SELECT 3 + 5;
SELECT id,username FROM users;
SELECT username,id FROM users;
SELECT users.id,users.suername FROM users;
SELECT id AS userid,username AS uname FROM users;
注释:SELECT 语法很强大,可以按所需要的查询表的结果,注意顺序不一样,显示结果不一样。另外查询表最好是加上表名称,因为可能多张表含同一字段。另外表的别名命名的AS 最好不要省略,省略可能会混乱(别名和字段名相同时会乱)。
查询表达式(select_expr)
⑴、查询某一个表达式的一列,必须有且至少一个。
⑵、多个列之间以英文逗号分隔。
⑶、星号(*)表示所有列。Tbl_name.*表示命名表的所有列。
⑷、查询表达式可以使用[AS] alias_name 为其赋予别名。
⑸、别名可用于GROUP BY ,ORDRE BY 或 HAVING 子句。
WHERE 条件表达式
对记录进行过滤,如果没有指定WHERE ,则显示或更改所有记录。
在WHERE表达式中,可以使用MySQL支持的函数或运算符。
GROUP BY (将查询后的结果进行分组)
[GROUP BY {col_name | position} [ASC | DESC],...]
例子:SELECT sex FROM users GROUP BY sex;
SELECT sex FROM users GROUP BY 1;
注释:ASC 为升序,DESC为降序。第一个列子是按名称进行分组,第二个是按位置。
HAVING (GROUP BY 的 分组条件)
[HAVING where_condition]
例子:SELECT sex FROM users GROUP BY 1 HAVING age > 35;
这个例子返回错误是因为 HAVING 的条件不是一个聚合函数或者 age 字段必须出现在分组中。因此有两个书写方式。
SELECT sex FROM users GROUP BY 1 HAVING count(id) > 35;
SELECT sex,age FROM users GROUP BY 1 HAVING age > 35;
注释:第一个例子 id 没有出现在查找的字段內,但是语法没错。第二个出现。
ORDER BY (对查询分组的结果进行排序)
[ORDER BY {col_name | expr | position} [ASC | DESC],...]
例子:SELECT * FROM users;
SELECT * FROM users ORDER BY id DESC;
SELECT * FROM users ORDER BY age;
SELECT * FROM users ORDER BY age,id DESC;
注释:第一个例子遵守了原顺序排列,也是查询结果的正常语法,后面的例子都有查询只是按不同条件显示结果。第二个按id 进行降序排序(从大到小)。每个例子的语句排列结果只是对查询分组后的结果进行排序,即第三个例子的语法会对第二个例子执行后的结果再排序。而第四个例子表面先按age排序,再按第二条件id排序。
LIMIT (限制查询结果返回的数量)
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
例子:SELECT * FROM users LIMIT 2;
SELECT * FROM users LIMIT 2,2;
注释:第一个例子返回自然查询结果的前两条记录。第二个例子是返回自然查询结果(如果是降序就是降序)中的第三个结果(含本身)后面的2个结果。因为第一条记录计算机默认为第0条。这条语句可以应用于PHP进行分页效果的实现。
当SELECT 查询数据显示出来乱码,可以使用命令:SET NAMES gbk;
使用这个命令转换的是客户端的数据,并不会影响数据库里面原本的数据。
第四部分:子查询与连接
子查询(Subquery)是指出现在其他SQL语句內的SELECT 子句。
例如:SELECT * FROM t1 WHERE col1 = (SELECT col2 FROM t2);
其中 SELECT * FROM t1 称为 Outer Query / Outer Statemen外层查询/外层声明
SELECT col2 FROM t2 称为SubQuery 子查询
、子查询指嵌套在查询语句内部,且必须始终出现在圆括号內。
‚、子查询可以包含多个关键字或条件。如:DISTINCT、GROUP BY 、ORDER BY 、LIMIT、函数等。
ƒ、子查询的外层查询(这里的查询是指SQL命令语句的统称,而不是单纯的查找。SQL又被称为结构化查询语言)可以是:SELECT,INSERT,UPDATE,SET或DO。
子查询返回的结果可以为:标量、一行、一列或子查询。
使用比较运算符的子查询
符号: = > < >= <= <> != <=>
语法结构: operand comparison_operator subquery
例子: SELECT AVG(goos_price) FROM tdb_goods;
SELECT ROUND(AVG(goods_price),2) FROM tdb_goods;
SELECT goods_id,goods_name,goods_price FROM tdb WHERE goods_price >= 5636.36;
SELECT goods_id,goods_name,goods_price FROM tdb WHERE goods_price >= (SELECT ROUND(AVG(goods_price),2) FROM tdb_goods);
SELECT goods_price FROM tdb_goods WHERE goods_cate = ‘超级本’;
SELECT * FROM tdb_goods WHERE goods_cate = ‘超级本’\G;
⑴、比较运算符的 修饰关键字 ANY SOME ALL (返回值)
> 、 >= 最小值 最大值
< 、 <= 最大值 最小值
= 任意值
<> 、 != 任意值
SELECT goods_id,goods_name,goods_price FROM tbd_goods WHERE goods_price >= ANY (SELECT goods_price FROM tbd_goods WHERE goods_cate = ‘超级本’);
注释:第一条到第三条都是正常的查询,第一条査平均值,AVG后面补充。第二条是四舍五入取2位。第三条例子是综合第一个和第二个例子。第四个例子是子查询语句。最后一个例子是带有修饰关键字的子查询(不带关键字会报错,因为查询结果可能会有很多个,没有指定比较方式从而无法比较报错。)
⑵、使用[NOT] IN 的子查询
语法结构:operand comparison_operator [NOT] IN (subquery)
=ANY 运算符与IN等效 !=ALL 或 <>ALL 运算符与NOT IN 等效。即上面的例子中的部分可以与IN 和 [NOT] IN 互相替代。
⑶、使用[NOT] EXISTS 的子查询
如果子查询返回任何行,EXISTS 将返回TRUE;否则为FALSE 这类用的较少。
优化数据库之数据优化
当某一分类信息重合度非常高时,比如上面的商品分类goods_cate和商品品牌brand_name,我们需要将这一类的数据进行整合,以便当数据条目非常多时,减少数据库的大小并加快查询更新速度。①、下面语句就可以很快查询出goods_cate的类别数目。
SELECT goods_cate FROM tdb_goods GROUP BY goods_cate;
而我们可以②、新建一张新表,用于存储上面的goods_cate并且进行自动编号,
CREATE TABLE IF NOT EXISTS tdb_goods_cates(
cate_id SMALLINT UNSIGNED PRIMARY KEY AUTO_INCREMENT,
Cate_name VARCHAR(40) NOT NULL);
③、再将第一张里面的类别存储到这个新表中(利用INSERT 第三种方法写入),
假设不知道列的名称,利用命令查询先:DESC tdb; (这个应该是已经在新表中才使用,已知列的名称这一步可以省略)

⑵、连接条件:ON conditional_expr
将上面优化步骤进行进一步简化
①、CREATE...SELECT (创建数据表同时将查询结果写入到数据表)
此处内容省略....有需要的请直接评论中留言
CREATE TABLE tdb_goods_types(
type_id SMALLINT UNSIGNED PRIMARY KEY AUTO_INCREMENT,
type_name VARCHAR(20) NOT NULL,
parent_id SMALLINT UNSIGNED NOT NULL DEFAULT 0);
自身连接:同一个数据表对其自身进行连接。
例子:初始数据表状态:
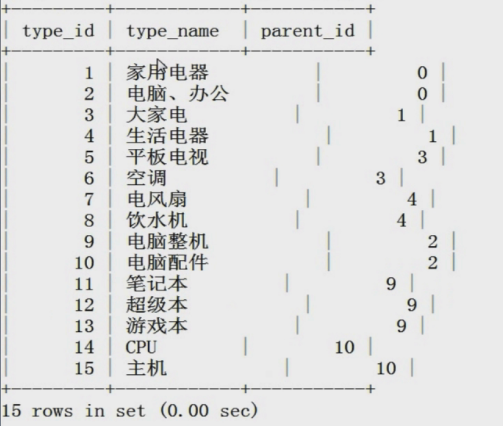
第一个例子查询(一级)父类名称,没有父类用NULL填入;
SELECT s.type_id,s.type_name,p.type_name FROM tdb_goods_types AS s LFET JOIN tdb_goods_types AS p ON s.parent_id = p.type_id;

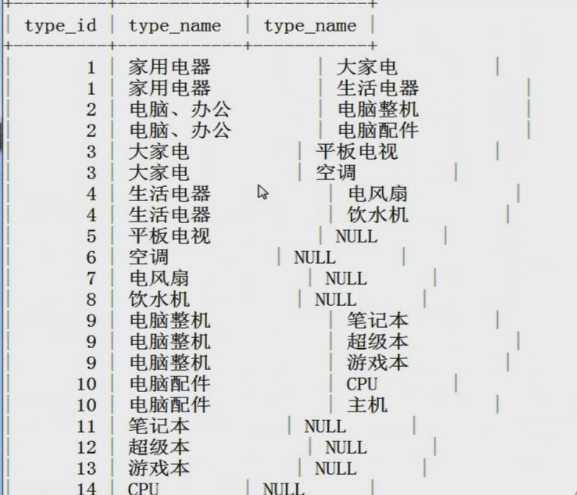
第二个例子查询子类名称,没有子类用NULL填入。
SELECT p.type_id,p.type_name,s.type_name FROM tdb_goods_types AS p LEFT JOIN
tdb_goods_types AS s ON s.parent_id = p.type_id;
第三个例子查询子类通过p.type_name分组。
SELECT p.type_id,p.type_name,s.type_name FROM tdb_goods_types AS p LEFT JOIN
tdb_goods_types AS s ON s.parent_id = p.type_id GROUP BY p.type_name;

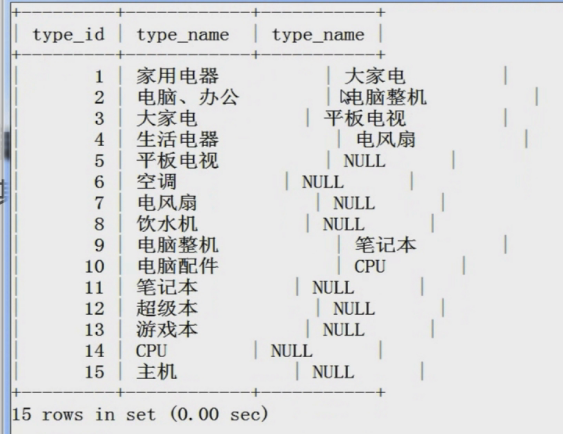
第四个例子:查询子类通过p.type_name分组并且通过type_id进行排序。
SELECT p.type_id,p.type_name,s.type_name FROM tdb_goods_types AS p LEFT JOIN
tdb_goods_types AS s ON s.parent_id = p.type_id GROUP BY p.type_name ORDER BY p.type_id;
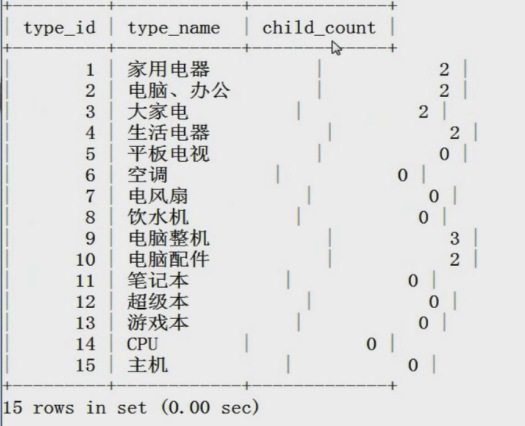
第五个例子:查询子类数量。
SELECT p.type_id,p.type_name,count(s.type_name) child_count FROM tdb_goods_types AS p LEFT JOIN tdb_goods_types AS s ON s.parent_id = p.type_id GROUP BY p.type_name ORDER BY p.type_id;
多表删除(也可以视作重复记录删除)
DELETE tbl_name[.*] [,tbl_name[.*]]...
FROM table_references
[WHERE where_condition]
例子:
⑴、查找商品ID号和名称按商品名称分组显示。
SELECT goods_id,goods_name FROM tdb_goods GROUP BY goods_name;

⑵、查找商品的ID号和名称(条件为:重复)
SELECT goods_id,goods_name FROM tdb_goods GROUP BY goods_name HAVING count(goods_name) >= 2;

⑶、参照上图中的表删除上上图中的重复数据(多表删除操作)。
DELETE t1 FROM tdb_goods AS t1 LEFT JOIN (SELECT goods_id,goods_name FROM tdb_goods GROUP BY goods_name HAVING count(goods_name) >= 2) AS t2 ON t1.goods_name = t2.goods_name WHERE t1.goods_id > t2.goods_id;
注释:删除tdb_goods 别名t1 需要连接自身 将括号內的查询结果作为新表别名 t2 ,ON 条件:t1.goods_name = t2.goods_name , 没有WHERE 则将所有名字相同的记录全部删除,WHERE t1.goods_id > t2.goods_id 加上WHERE语句意思就是 保留ID小的记录。
第五部分:运算符和函数
字符函数
函数名称(原函数括号内无内容) 描述

例子:
SELECT CONCAT(first_name,last_name) AS full_name FROM test; 字段名不用加引号
SELECT CONCAT_WS('|','A','B','C'); 结果:A|B|C
SELECT LOWER(LEFT('MySQL',2)); 嵌套函数,结果:my
SELECT LENGTH(TRIM(' MySQL ')); 结果是:5
SELECT TRIM(LEADING '?' FROM '??MySQL???'); 这个意思是删除前导的?号,LEADING '?'代表前导,返回结果MySQL??? 如果为TRAILING '?' 则结果为: ??MySQL 如果为BOTH '?' 则返回的结果为MySQL
SELECT REPLACE('??MY??SQL??','?',''); 将字符里面的问号替换为空,结果为MYSQL
SELECT * FROM test WHERE first_name LIKE '%o%'; 查看test表first_name中是否有匹配o的数据。% 与windows 中的* 一致,代表任意的通配符,而下划线_代表任意一个字符。但是如果查询含有%的数据,则为:
SELECT * FROM test WHERE first_name LIKE '%1%%' ESCAPE '1'; 告诉程序1后面的%不用解析了,就可以查询test表first_name中是否有匹配% 的数据。
数值运算符与函数
数值运算符 + - * /
函数名称 描述 例子 结果
CEIL() 进一取整,向上取整。 SELECT CEIL(3.01); 4
DIV 整数除法 SELECT 3 DIV 4; 0 这个要测试一下
FLOOR() 舍一取整,向下取整。 SELECT FLOOR(3.99); 3
MOD 取余数,取模。 SELECT 5 % 3 ; SELECT 5 MOD 3; 2 余数为2
POWER() 幂运算 SELECT POWER(3,3); 27 3的3次方
ROUND() 四舍五入 SELECT ROUND(3.65,1); 3.7
TRUNCATE() 数字截取 SELECT TRUNCATE(152.85,1) 152.8 1代表小数点后面1位数,如果是0结果为152,如果是-1代表小数点前面1位 结果为150
[NOT] BETWEEN...AND... [不]在范围之内 SELECT 15 BETWEEN 1 AND 22; 返回1代表在这个范围之内。返回0代表不在这个范围之内。
[NOT] IN() [不]在列出值范围内 SELECT 10 IN(5,15,10,20); 返回1;而如果是 SELECT 11 IN(5,15,10,20); 则返回值为0。
IS [NOT] NULL [不]为空 SELECT '' IS NULL; 返回0。SELECT NULL IS NULL; 返回1。SELECT 0 IS NULL; 返回0。 SELECT * FROM test WHERE first_name IS NULL; 返回test该表中first_name为NULL的数据。
日期时间函数
函数名称 描述 例子
NOW() 当前日期和时间 SELECT NOW();
CURDATE() 当前日期 SELECT CURDATE();
CURTIME() 当前时间 SELECT CURTIME();
DATE_ADD() 日期加减 SELECT DATE_ADD('2016-12-16',INTERVAL 365 DAY);
结果为2017-12-16,INTERVAL为量词。365可以为负值,DAY单位可以变
DATEIFF() 日期差值 SELECT DATEDIFF('2016-12-16','2017-12-16'); 结果为-365
DATE_FORMAT()日期格式化 SELECT DATE_FORMAT('2016-12-8','%m/%d/%Y');
返回结果为12/08/2016 %m中的%为前导零,假如月份为9,会自动补充09
信息函数
函数名称 描述 例子
CONNECTION_ID() 连接数据库的ID SELECT CONNECTION_ID();
DATEBASE() 当前数据库 SELECT DATEBASE();
USER() 当前用户 SELECT USER();
VERSION() 当前版本信息 SELECT VERSION();
LAST_INSERT_ID() 最后插入记录的ID SELECT LAST_INSERT_ID(); 如果同时写入多
条记录,则只显示多条记录的第一天记录插入的ID号。
聚合函数(特点:只有一个返回值)
函数名称 描述 例子
AVG() 平均值 SELECT AVG(goods_price) AS avg_price FROM tdb_goods;
COUNT() 计数 SELECT COUNT(goods_id) AS counts FROM tdb_goods;
MAX() 最大值 SELECT MAX(goods_price) AS count_price FROM tdb_goods;
MIN() 最小值
SUM() 求和
SELECT ROUND(AVG(goods_price),2) AS avg_price FROM tdb_goods;
加密函数
函数名称 描述 例子 用途
MD5() 信息摘要算法 SELECT MD5('123'); 用于WEB页面
PASSWORD() 密码算法 SELECT PASSWORD('123'); 用于MYSQL客户端密码
例如修改密码:SET PASSWORD=PASSWORD('ABC');
自定义函数:
用户自定义函数(user_defined function,简称UDF)是对一种MySQL扩展的途径,去用法与内置函数相同。自定义函数的两个必要条件:参数和返回值。而返回值是所有函数都有的,数量可以不同,参数有的函数则没有,参数和返回值之间没有必然的联系。
函数可以返回任意类型的值,也可以接收这些类型的参数。创建自定义函数,理论上参数数量可以达到1024个。
创建自定义函数语法:
CREATE FUNCTION function_name
RETURNS
{STRING|INTEGER|REAL|DECIMAL}
routine_body
关于函数体(routine_body)
⑴、函数体由合法的SQL语句构成;
⑵、函数体可以是简单的SELECT或INSERT语句;
⑶、函数体如果为复合结构则使用BEGIN...END语句;
⑷、复合结构可以包含声明,循环,控制结构;
创建自定义函数:
不带参数的例子:
SET NAMES gbk;
SELECT NOW();
SELECT DATE_FORMAT(NOW(),'%Y年%m月%d日 %H点:%i分:%s秒');
CREATE FUNCTION f2() RETURNS VARCHAR(30)
RETURN DATE_FORMAT(NOW(),'%Y年%m月%d日 %H点:%i分:%s秒');
注意:第一条设置GBK语句不能漏,否则出错。第二、三条只是过程。第四条是创建自定义函数,如果创建了自定义函数但又不能正确执行,而且会占用。比如f1已经被占用了,需要删除这个自定义函数的f1。命令:DROP FUNCTION f1;
语法:DROP FUNCTION [IF EXISTS] function_name
SELECT f2(); 调用函数。
带参数的例子:
CREATE FUNCTION f1(num1 SMALLINT UNSIGNED,num2 SMALLINT UNSIGNED)
RETURNS FLOAT(10,2) UNSIGNED
RETURN (num1+num2)/2;
SELECT f1(35,55);
创建具有复合结构函数体的自定义多参数函数的例子
DELIMITER // 设定//作为语句分隔符替代;
CREATE FUNCTION adduser(username VARCHAR(20))
RETURNS INT UNSIGNED
BEGIN
INSERT test(username) VALUES(username);
RETURN LAST_INSERT_ID();
END//
SELECT adduser('Rose');
返回值 3
DELIMITER ;
注释:因为有2个语句需要执行,所以需要添加第一行,而且需要用BEGIN...END标记起来。returns定义的是函数返回值的类型而return则返回的是返回值

